

PYTHON DATA SCIENCE
DATA SCIENCE
Data science is a multidisciplinary field that uses various techniques, algorithms, processes, and systems to extract insights and knowledge from data. It combines elements of statistics, computer science, and domain knowledge to analyze and interpret complex data sets. Data scientists collect, clean, and analyze data, often using tools like Python, R, and machine learning algorithms, to uncover patterns, make predictions, and inform decision-making. It has applications in a wide range of industries, from healthcare and finance to marketing and technology.
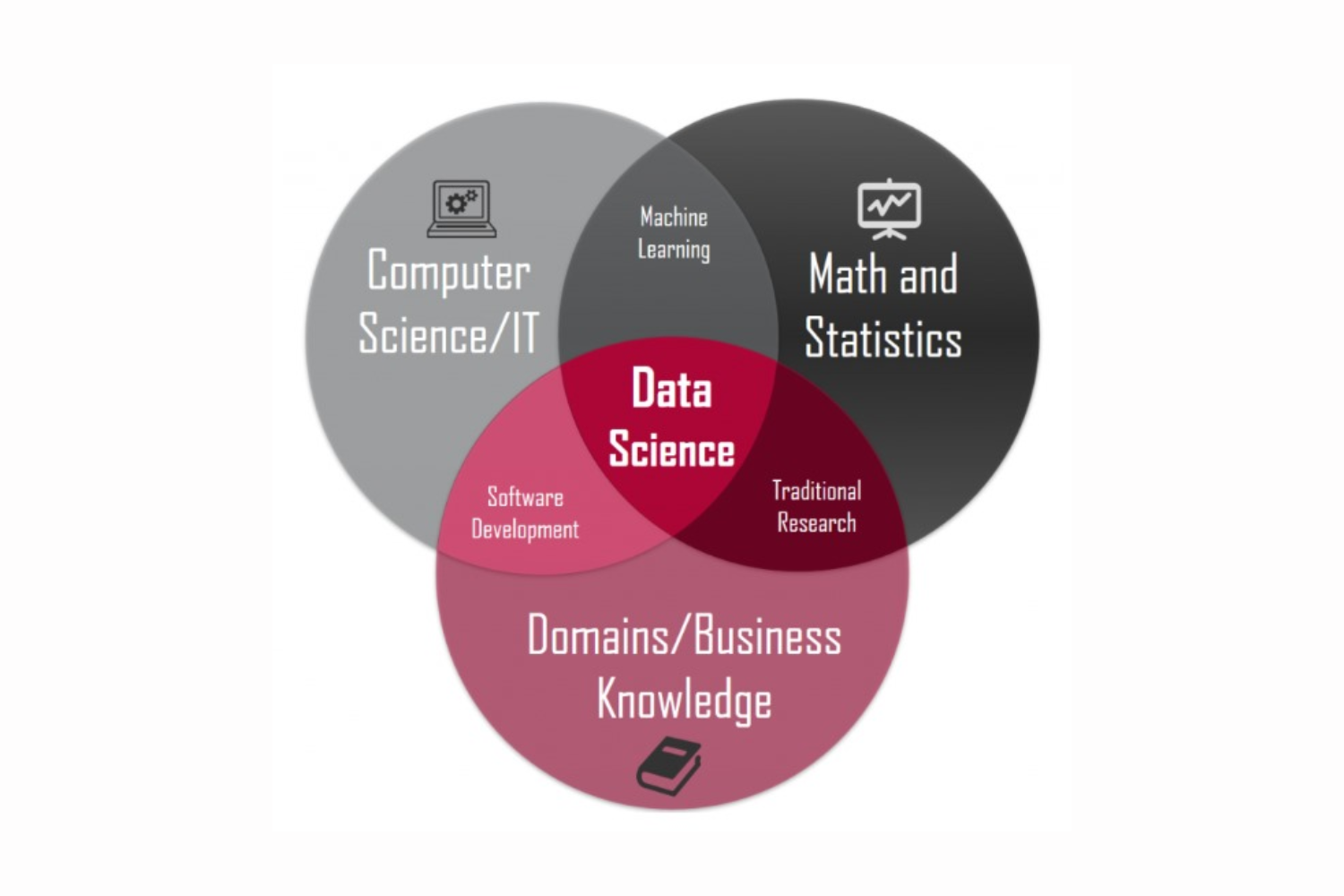
UNDERSTANDING THE FUNDAMENTALS
Data science involves extracting insights and knowledge from data. Its fundamentals include:
Data Collection: Gathering relevant data from various sources.
Data Cleaning: Removing errors and inconsistencies from data.
Exploratory Data Analysis (EDA): Understanding data patterns and relationships through visualization and summary statistics.
Feature Engineering: Selecting, transforming, and creating features to improve model performance.
Modeling: Use statistical, machine learning, or deep learning techniques to build predictive or descriptive models. Common algorithms include linear regression, decision trees, and neural
Training and Testing: Split your data into training and testing sets to evaluate your model’s performance and prevent overfitting.
Evaluation: Use metrics like accuracy, precision, recall, or Mean Squared Error to assess how well your model performs.
Validation: Use cross-validation techniques to ensure your model’s generalizability to new data.
Deployment: Implement your model into a real-world application or system.
Monitoring and Maintenance: Continuously monitor and update models to adapt to changing data patterns.
Ethics and Privacy: Consider the ethical implications of data collection and model outcomes, and ensure data privacy and security.
Domain Knowledge: Understanding the domain you’re working in is crucial for interpreting results and making informed decisions
PYTHON A PREFFERED CHOICE FOR DATA SCIENCE
Python is a preferred choice for data science for several reasons:
Extensive Libraries: Python has a rich ecosystem of data science libraries, including NumPy, Pandas, Matplotlib, Seaborn, and Scikit-learn, which provide powerful tools for data manipulation, analysis, visualization, and machine learning.
Versatility: Python is a versatile language that can be used for various data science tasks, from data cleaning and analysis to building machine learning models. Its flexibility allows data scientists to work on end-to-end projects.
Community Support: Python has a large and active community of data scientists and developers. This means there is a wealth of online resources, forums, and packages readily available for support and collaboration.
Integration: Python seamlessly integrates with other technologies commonly used in data science, such as SQL databases, Hadoop, Spark, and cloud computing platforms. This makes it easier to work with diverse data sources and tools.
Ease of Learning: Python is known for its readability and simplicity, making it accessible for beginners and experts alike. Data scientists often find it easier to learn and use Python compared to other languages.
Open Source: Python is open source, which means it’s cost-effective and adaptable. It’s constantly evolving, with a community that contributes to its improvement.
Visualization: Python offers a range of libraries for data visualization, such as Matplotlib, Seaborn, and Plotly, making it easy to create meaningful and insightful charts and graphs.
Machine Learning and Deep Learning: Python has gained popularity in machine learning and deep learning, largely due to libraries like Scikit-learn, TensorFlow, and PyTorch, which simplify the development of complex models.
Reproducibility: Python supports Jupyter Notebooks and other tools that facilitate reproducible research, a crucial aspect of data science.
Job Market: Python’s prevalence in data science has led to a strong demand for Python-skilled data scientists, making it a practical choice for career opportunities.
These factors, among others, have made Python the go-to language for Data Science and analysis.

SCOPE OF PYTHON DATA SCIENCE
The scope of Python data science is quite extensive and continues to grow. It is widely used in various fields, including business, healthcare, finance, social sciences, and more, for tasks like predictive modeling, data-driven decision-making, and uncovering patterns in data. As data becomes increasingly valuable, the demand for data scientists and analysts proficient in Python is expected to remain high, making it a promising career choice. Additionally, Python’s open-source nature and a vibrant community contribute to its ongoing development and relevance in the data science domain.
JOB ROLES
1. Data Scientist
2. Data Analyst
3. Machine Learning Scientist
4. Data Engineer
5. Machine Learning Engineer
6. Statistician
7. Data Architect
8. Business Intelligence Developer
9. Applications Architect
10. Infrastructure Architect
11. Enterprise Architect
SALARY
Python Data Scientist salary in India is expected to be 13 lakhs to 35 lakhs per annum .
The average salary of a Python Data Scientist in India can vary depending on a number of factors, such as experience, location, and company size.
PYTHON DATA SCIENCE TECHNOLOGIES
Python is a highly popular and versatile programming language in the field of data science. It offers a wide range of technologies, libraries, and tools to help data scientists and analysts work with data efficiently. Here are some of the key Python data science technologies:
NumPy: NumPy is the fundamental library for numerical computing in Python. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays. NumPy is a foundation for many other data science libraries.
Pandas: Pandas is a powerful data manipulation and analysis library. It provides data structures like DataFrames and Series for handling structured data, making it easier to clean, transform, and analyze datasets.
Matplotlib: Matplotlib is a widely-used library for creating static, animated, and interactive visualizations in Python. It offers a range of charting options for data visualization.
Seaborn: Seaborn is a high-level data visualization library built on top of Matplotlib. It simplifies the creation of informative and attractive statistical graphics.
Scikit-Learn: Scikit-Learn is a comprehensive machine learning library for Python. It provides tools for data preprocessing, model selection, evaluation, and deployment. It is particularly useful for traditional machine learning algorithms.
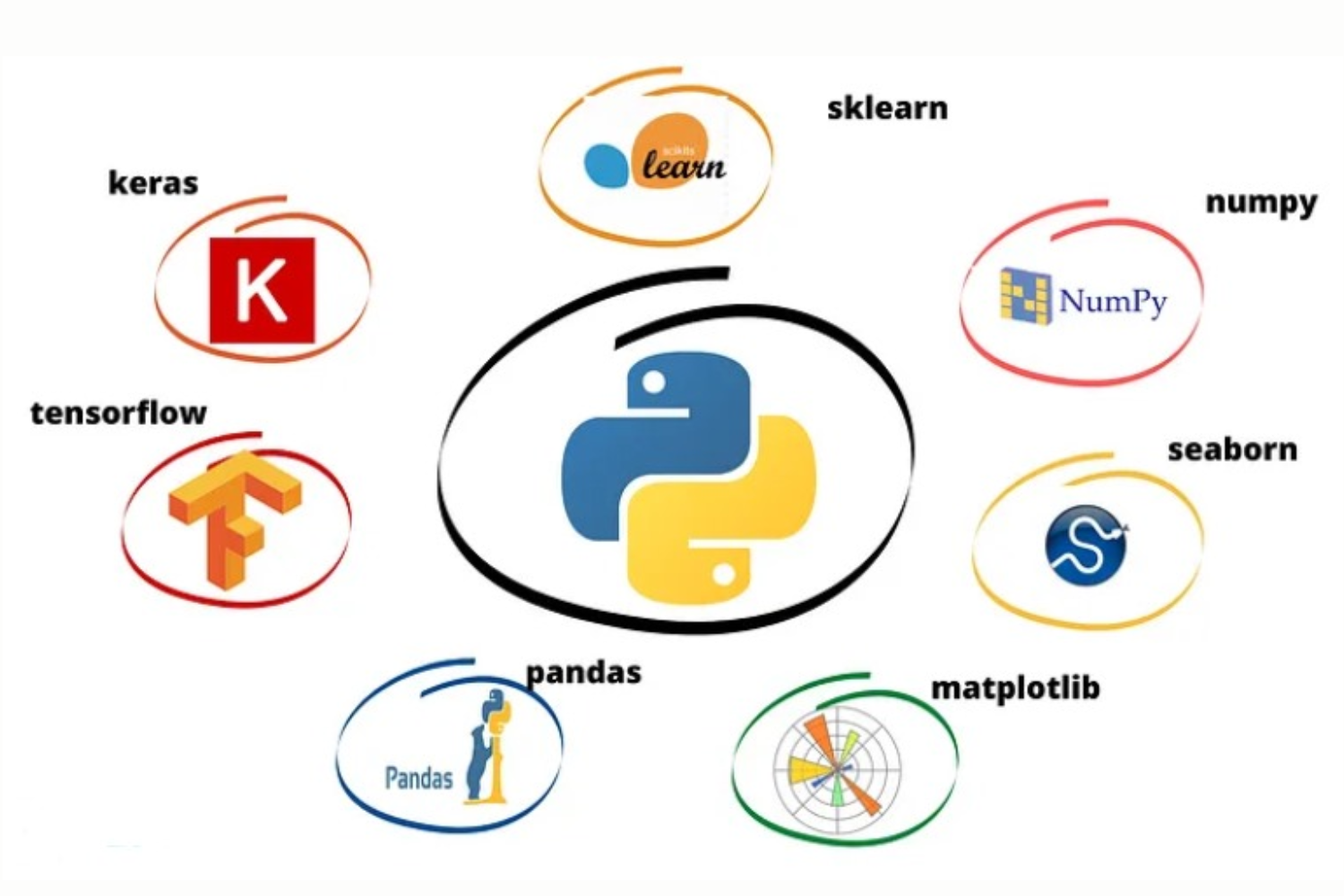
TensorFlow and PyTorch: These are popular deep learning frameworks used for developing and training neural networks. TensorFlow and PyTorch are widely employed in the field of deep learning and artificial intelligence.
Keras: Keras is a high-level neural networks API that can run on top of TensorFlow, Theano, or Microsoft Cognitive Toolkit (CNTK). It simplifies the process of building and training neural networks.
Jupyter Notebook: Jupyter Notebook is an interactive web-based environment that allows data scientists to create and share documents containing live code, equations, visualizations, and narrative text. It’s an essential tool for data analysis and documentation.
SQL Databases: Python provides various libraries for connecting to SQL databases, such as psycopg2, sqlite3, and pyodbc, enabling data retrieval, storage, and analysis.
NoSQL Databases: Python libraries like pymongo are used to interact with NoSQL databases like MongoDB, making it possible to work with unstructured data.
Natural Language Processing (NLP): Python libraries like NLTK (Natural Language Toolkit), spaCy, and gensim are commonly used for text processing and NLP tasks.
Data Wrangling and Cleaning: Tools like OpenRefine and libraries like Dask can help with data cleaning, transformation, and wrangling.
Big Data Processing: For big data analysis, technologies like Apache Spark can be accessed from Python using PySpark.
Data Visualization: Beyond Matplotlib and Seaborn, libraries like Plotly, Bokeh, and Altair offer interactive and web-based data visualization capabilities.
Statistical Analysis: The statsmodels library is used for statistical modeling and hypothesis testing.
Geospatial Data: Libraries like GeoPandas and Folium help in working with geospatial data and creating interactive maps.
Time Series Analysis: Libraries like statsmodels and Prophet (developed by Facebook) are used for time series analysis.
Data Version Control: Tools like Git and libraries like DVC (Data Version Control) are important for managing and tracking changes to data and code in data science projects.
These technologies form the core of the Python data science ecosystem.
COURSE HIGHLIGHTS
1- Suited for students, freshers, professionals, and corporate employees
2- Live online classes
3- 4-month program
4- Certificate of completion
5- Decision Oriented Program of Analysis
6- Live Classes by highly experienced faculties
7- Hands-on experience with real-life case studies

Conclusion
Data science is not just another trend that will fade away but it is a principle need of modern businesses to survive in the competition .Therefore organisations require professionals with in -&- out knowledge of these growing technologies and hands on experience. keeping the innate need in mind, SCODEEN GLOBAL has launched python DATA SCIENCE COURSE that will help you gain expertise in various industry skills and technologies.